
How long can the money spent on training large models last?
- BedRock
- Aug 12, 2024
- 7 min read
We have assessed the computational power requirements for future large model training, concluding that with each generation upgrade, the demand for computational power increases exponentially. If there isn't a positive commercial cycle in place, it will become increasingly challenging to keep up.
Referring to MS's estimates, we adjusted the parameters based on our understanding to calculate the computational power required for training each generation of large models under different scenarios. The core variables include model parameters, training days, GPU performance, and unit price. At least for now, the process of upgrading large models is still accompanied by a multiplicative increase in the number of parameters. Therefore, by using the number of model parameters, we can derive the required tokens for training. Based on the computational power required per token, we can calculate the total computational power demand. Assuming the training days for each generation of models are appropriately extended, we can estimate the GPU Capex required for training each generation. The table below assumes the prices for A, H, B, and "R" cards to be $11,000, $25,000, $35,000, and $60,000 respectively.
Based on MS's calculations and adjusting the assumptions according to NVDA's current roadmap, here are our estimates for Bull, Base, and Bear cases:



Conclusion:
Training GPT-4: With 1,760 billion parameters and 100 days of training, it requires 25,000 A100 GPUs, with a Capex for purchasing the cards of less than $300 million.
Training GPT-5: With parameters ranging from 8,800 billion to 15 trillion and 150 days of training, it requires 150,000 to 260,000 H100 GPUs, corresponding to a Capex of $3.7 billion to $6.6 billion for purchasing the cards.
Training GPT-6: With parameters ranging from 35 to 85 trillion and 200 days of training, it requires 580,000 to 2.32 million B100 GPUs, corresponding to a Capex of $20 billion to $81 billion for purchasing the cards. For 60 trillion parameters, it would require around $43 billion.
Training GPT-7: With parameters ranging from 106 to 340 trillion and 250 days of training, it requires 450,000 to 7.2 million "R"100 GPUs, with a Capex of $27 billion to $430 billion for purchasing the cards. For 180 trillion parameters, it would require around $130 billion.
What does spending $100 billion mean for the giants? Let's take a look at the Capex situation of the tech giants:
Microsoft: In FY24, Capex is projected to be between $70-75 billion, with only 50% related to equipment, amounting to $35-38 billion. The rest is for building and leasing data centers (intended for the next 15 years). Additionally, the equipment investment includes both CPUs and GPUs, covering both Cloud and AI investments. (Experts have indicated that Microsoft is purchasing around 700,000 GPUs this year, which aligns with this figure.)
Google: In FY24, Capex is estimated at $50-55 billion.
Meta: In 2024, Capex is projected to be $37-40 billion. Meta is developing open-source large models, but with much smaller parameter counts. The current Llama 3 model has around 400 billion parameters (compared to GPT-4's 1.7 trillion and GPT-5's rumored 8.8 trillion). By the end of the year, Meta will have 600,000 GPUs. Training Llama 3 requires 16,000 GPUs, and the next generation, Llama 4, will require 160,000 GPUs (as disclosed by Zuckerberg in interviews and earnings calls). The current 600,000 GPUs support three purposes: 1) simultaneously training two generations of models (we have needed to train prior generations and the next generation of Llama); 2) recommendation algorithms; and 3) preparing for future needs, as Llama 4 is not the end, with Llama 5 and 6 still to come.
Amazon: In FY24, Capex is expected to be $65 billion (with $30 billion in the first half and more projected in the second half, mostly invested in AWS). This also includes logistics (with experts suggesting an investment of $180 billion between 2024 and 2040) and AI investments. If we look at the increase, it's $17 billion more than FY23 (experts indicate that Amazon is purchasing 400,000 GPUs this year, which aligns with this figure).
From this, we can see that while the total Capex for these giants appears large, the actual amount spent on purchasing GPUs is in the low hundreds of billions. These companies typically generate revenues in the low trillions, with operating cash flows in the hundreds of billions. If buying GPUs alone requires spending $100 billion without being sure when sufficient cash flow will return, it would be a difficult decision. As models evolve to GPT-7.0, a company would need to spend nearly $100 billion on GPUs, significantly exceeding current investments by mega-corporations. Without normal revenue and cash flow feedback, it will become increasingly challenging to keep up.
What are the current reactions of the tech giants?
The prospects of AGI (Artificial General Intelligence) are incredibly enticing, and staying in the game is crucial to ensuring a share of the potentially enormous rewards (there’s a strong belief that whoever achieves AGI first will capture the vast majority of the market, leaving very little for the second-place competitor). The fear of missing out is significant.
The giants are also aware of the exponential increase in computational power required for subsequent model training. As a result, many are front-loading their investments, as indicated by clear statements from companies like Microsoft and Meta. This strategy helps distribute the pressure of massive investment increases over several years. They are hoping that the capabilities of the next generation or the one after will improve significantly, enabling commercialization, or that smaller, more achievable commercial successes using smaller models will ease the financial burden of training large models. (However, it's worth noting that Meta is investing in much smaller open-source models, following a completely different path from OpenAI's large models, which means less financial strain down the line.)
Overall, most of the early investments are going into the construction of data centers, including buildings, server rooms, and energy infrastructure. Purchasing GPUs too early isn’t cost-effective (as newer GPUs will have a better cost-performance ratio). Therefore, when a company’s computational investment demand reaches the scale of hundreds of billions of dollars, making that decision without a significant cash return is still very challenging.
If we project forward, when large models iterate to the GPT-7.0 level, how many companies will still be able to keep up, and what does this mean for NVIDIA?
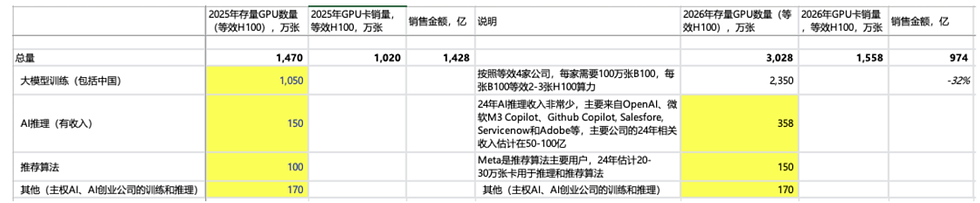
If we roughly calculate, NVIDIA's cumulative sales of GPUs (referring to those used in data centers) are estimated to reach 4.5 million units by 2024, with about 2 million units used for training, and the rest for AI inference, traditional recommendation algorithms, and other uses. By 2025, the proportion of GPUs used for large model training will increase significantly, with other uses becoming less important over the next few years.

More critically, by 2026, when each company needs to invest around $100 billion to train models (equivalent to training a GPT-7.0 level model) and there is still insufficient cash flow, how many companies will be able to continue this investment?
Let's calculate different scenarios:
If 2 companies can still follow through, NVIDIA's GPU sales revenue in 2026 could still see around a 30% increase, though overall growth might be slower.
If only 1 company continues, there could be a ~30% decline.
If 3 companies keep up, there could still be ~90% high growth.
Overall, how many companies can continue to invest is crucial for NVIDIA. Other factors to consider include whether large model upgrades will still require exponential increases in parameters, whether customers might extend training times to reduce yearly expenditures, and whether NVIDIA might lower prices to ensure a win-win situation.
Scenario 1: Assuming 2 companies can continue to invest, this would correspond to an equivalent of around 15 million H100 GPUs (by then, the primary sales card should have advanced to the R series). The R series GPU's computational power is equivalent to 4x the B series and 8-12x the H series. Pricing will be crucial by then. If the pricing is set at $50,000-60,000, equivalent to 1.5x the B series, it would result in about $100 billion in GPU sales revenue, which is approximately a 30% decline compared to 2025. If the R series is priced higher, it means each company will have to invest even more in GPUs.

Scenario 2: There are 3 companies that can follow suit, and the card sales revenue will increase by ~90% in 26 years.

Scenario 3: If only one company can follow up, the card sales revenue will decline by 30% in 26 years.
For NVIDIA, the critical points are:
Whether the computational power demand for training each generation of models will grow exponentially;
Whether commercial applications will materialize in 2025-2026 and bring back sufficient cash flow;
How many companies will be able to keep up with the continuous upgrades and training of large models.
Should we still persist with large model upgrades, considering the rapid progress of small models?
Small models are advancing very quickly and are closer to commercialization. Every 8 months, the knowledge density of small models doubles (a 10 billion parameter model will have the capabilities of a 20 billion parameter model after 8 months). Currently, a 13 billion parameter model has reached the level of GPT-3.5 (175 billion parameters), and by 2026-2027, it could reach the level of GPT-4. Next year, a 7 billion parameter model could also reach the level of GPT-3.5. Meta's recently released Llama 3.0 is reportedly at the level of GPT-4.0. Before GPT-5.0 is released, small models are rapidly catching up.
GPT-3.0 was released in May 2020, GPT-3.5 in November 2022, and GPT-4.0 in April 2023. Currently, it has been 1 year and 3 months since GPT-4.0, and GPT-5.0 has not yet been released. If it is released at the end of the year, it will be nearly 2 years between versions.

Chart source: Jiuqian Consulting
Additionally, over the long term, the commercialization prospects for small models seem more promising:
Faster feedback;
Fewer hallucinations and higher reliability when addressing specific needs or scenarios;
Much lower costs, making it easier to justify the investment.
Currently, companies like Microsoft, ServiceNow, and Apple are embracing small models for commercialization, leveraging the capabilities of others' large models.
Looking ahead, the continued iteration of large models is likely to hit a cost ceiling unless a rapid path to monetization is found (e.g., if GPT-5, expected to be released at the end of the year, could potentially discover a new drug). Otherwise, progress may stall at GPT-6 (with 60 trillion parameters, requiring around $50 billion to purchase GPUs). In contrast, small models are more likely to achieve a positive feedback loop through commercialization. They can continue to advance by slowly increasing parameters while rapidly iterating the model.
Comments